蜜拉乔娃维琪用AI做出「满分项目」?开发者实测:是真有料还是夸大炒作?

蜜拉·乔沃维琪参与开发的 AI 记忆系统 MemPalace 宣称测试满分而爆红,却遭社群踢爆测试涉嫌作弊与数据误导。实测发现成效夸大且有大量错误,团队已承认瑕疵并着手修复中。
蜜拉·乔沃维琪打造AI记忆宫殿,引发外界关注
昨天(4/7)AI 圈有个大新闻是,以《生化危机》《第五元素》闻名的好莱坞女星蜜拉·乔沃维琪(Milla Jovovich),与开发者 Ben Sigman 使用 Claude Code 辅助开发出「MemPalace」开源 AI 记忆系统。
一时间,「好莱坞巨星跨界做出满分项目」的说法广泛流传,MemPalace 至今在 GitHub 上也获得超过 2 万颗星星,但很快地就引发开发者社群质疑:是真的有料还是炒作?
先来谈一下 MemPalace 誕生的动机,官方文件称是想解决目前 AI 系统使用者与 AI 的对话内容、决策过程与架构讨论通常会在工作阶段结束后消失,导致数个月的心血归零的限制。
为解决这个问题,MemPalace 采用空间架构来储存记忆,将信息明确归类至代表人员或项目的翼区,以及走廊、房间与抽屉等不同层级的结构中,保留对话原文供后续语意检索。
开发团队宣称,MemPalace 在长期记忆评估基准 LongMemEval 中获得 100% 的完美成绩,并且在不调用任何外部 API 的情况下达到 96.6% 的准确率,而且能完全在本地端运行,不需订阅云端服务,并搭载号称能达到 30 倍无损压缩的 AAAK 方言系统。
图源:GitHub 美国电影明星蜜拉·乔沃维琪打造AI记忆宫殿,引发外界关注
同行与社群齐质疑,测试方法与宣传存瑕疵
不过,MemPalace 号称 LongMemEval 满分的成绩,很快就引来同行质疑。
同样是制作 AI 记忆系统的 PenfieldLabs 指出,MemPalace 宣称在 LoCoMo 数据集获得满分,在数学上不可能发生,因为该数据集的标准答案本身就包含 99 个错误。
PenfieldLabs 分析发现,MemPalace 的 100% 成绩来自于将检索次数设为 50 次,但测试数据集对话的最高阶段数仅有 32 次,这代表系统直接绕过检索阶段,把所有数据交给 AI 模型阅读。
针对 LongMemEval 的 100% 成绩,开发团队被发现是针对开发集中出错的 3 个特定问题,编写专属修复代码,存在针对测试集作弊的嫌疑。

图源:Reddit同行 PenfieldLabs 指出,MemPalace 宣称在 LoCoMo 数据集获得满分,在数学上不可能发生
GitHub 使用者实测,基准测试有误导成分
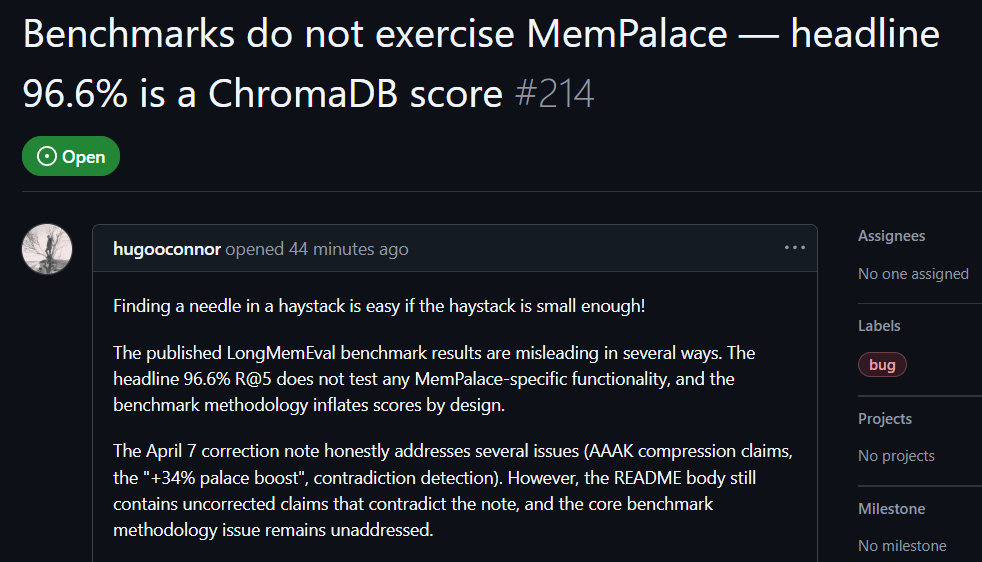
GitHub 使用者 hugooconnor 则在实测后评论,MemPalace 宣称高达 96.6% 的检索准确率,实际上完全没有使用到 MemPalace 标榜的记忆宫殿架构。hugooconnor 称,他们的测试只是调用底层数据库 ChromaDB 的预设功能,完全没有牵涉项目强调的翼区、房间或抽屉等分类逻辑。
hugooconnor 测试后发现,当系统真正启用这些记忆宫殿的专属分类逻辑时,检索成绩反而出现下滑。以房间模式为例,准确率下降至 89.4%,而启用 AAAK 压缩技术后,准确率更跌至 84.2%,两者皆低于预设数据库表现。
hugooconnor 也批评了测试方法,MemPalace 的测试环境刻意把每个问题的检索范围缩小至约 50 个对话阶段,在极小的样本库中寻找答案过于简单。
若把范围扩大到真实情境的 19,000 多个对话阶段,传统关键词搜索的准确率会暴跌至 30%,显示 MemPalace 目前的测试方式掩盖了真实的搜索难题。
图源:GitHub GitHub使用者实测,MemPalace基准测试有误导成分
同时,虽然开发团队已经发布更正声明,承认 AAAK 技术确实经过有损压缩,并承诺会根据社群的严厉批评修正说明文件与系统设计。但项目的主要说明文件依然保留多项未经修正的夸大说法,包含宣称 30 倍无损压缩与 34% 检索提升,并且与其他竞争对手的比较图表也完全缺乏来源出处。
MemPalace 原始码面临多项 Bug
随着越来越多开发者下载测试,目前 GitHub 平台上出现大量关于 MemPalace 原始码的 Bug 回报。
使用者 cktang88 列出多项严重瑕疵,包含压缩指令无法运作并导致系统崩溃、摘要字数计算逻辑错误、挖掘房间的统计数据不准确,以及服务器在每次调用时会将所有解析数据载入内存中,造成严重的资源消耗问题。
其他被指出的问题,还包括系统将开发者的家庭成员名称强制写入预设配置文件中,以及查询状态时存在 1 万笔数据的强制显示上限。
针对这些问题,开源社群已经开始积极修复。**使用者 adv3nt3 提交多项修复请求,包含修正挖掘统计数据、移除预设的家庭成员名称,以及延迟知识图谱的初始化时间。**开发团队后续也承认这些错误,正通过社群协作逐步解决代码问题。
蜜拉·乔沃维琪 Vibe Coding 很酷,行销方式不酷
对于 MemPalace 这个项目,Hacker News 网友 darkhanakh 下了一个结论:MemPalace 给人一种 OpenClaw 的既视感,也就是人为操纵基准测试(benchmark)结果使其看起来完美无瑕,然后再将其包装成某种重大突破来行销。
他认为,MemPalace 的底层技术可能确实很有意思,但在测试方法带有这类瑕疵的情况下,还主打「史上公开最高分」来宣传,实在不太妥当,「不过,蜜拉·乔沃维琪在玩 Vibe Coding 这件事,我想还是挺酷的啦。」
延伸阅读:
AI 写程式出包!超商即期品App「惜食猎人」爆资安问题,家中GPS全裸奔