
ระบบหน่วยความจำ AI MemPalace ที่ Milla Jovovich เข้าร่วมในการพัฒนา อ้างว่าทดสอบได้คะแนนเต็มและโด่งดังอย่างรวดเร็ว แต่กลับถูกชุมชนตรวจพบข้อสงสัยว่าอาจมีการโกงการทดสอบและการทำให้ข้อมูลคลาดเคลื่อน จากการทดสอบจริงพบว่าผลลัพธ์ถูกกล่าวอ้างเกินจริงและมีข้อผิดพลาดจำนวนมาก ทีมงานได้ยอมรับข้อบกพร่องแล้วและกำลังดำเนินการแก้ไขอยู่
Milla Jovovich สร้าง AI Memory Palace ทำให้สาธารณชนให้ความสนใจ
เมื่อวานนี้ (4/7) ในวงการ AI มีข่าวใหญ่ว่า นักแสดงสาวฮอลลีวูด Milla Jovovich (Milla Jovovich) ที่เป็นที่รู้จักจาก Resident Evil และ The Fifth Element ได้ร่วมกับนักพัฒนา Ben Sigman ในการใช้ Claude Code เพื่อช่วยพัฒนา “MemPalace” ระบบหน่วยความจำ AI แบบโอเพนซอร์ส
ชั่วขณะหนึ่ง คำกล่าวที่ว่า “ดาราใหญ่ฮอลลีวูดข้ามสายงาน ทำโปรเจกต์ที่ได้คะแนนเต็ม” แพร่กระจายอย่างกว้างขวาง และจนถึงตอนนี้ MemPalace บน GitHub ก็ยังได้รับมากกว่า 2 หมื่นสตาร์ แต่ไม่นานก็ทำให้ชุมชนนักพัฒนาตั้งคำถามอย่างรวดเร็วว่า: ของจริงมีคุณภาพ หรือเป็นเพียงการโปรโมตเกินจริง?
ก่อนอื่นมาพูดถึงแรงจูงใจที่ทำให้ MemPalace ถือกำเนิด ตามเอกสารทางการระบุว่า ต้องการแก้ปัญหาในปัจจุบันที่ “เนื้อหาบทสนทนากับ AI กระบวนการตัดสินใจ และการอภิปรายเกี่ยวกับโครงสร้าง” ของผู้ใช้ AI มักจะหายไปหลังจบช่วงทำงาน ทำให้ความพยายามที่ทุ่มเทมาหลายเดือนกลายเป็นศูนย์
เพื่อแก้ปัญหานี้ MemPalace จึงใช้สถาปัตยกรรมเชิงพื้นที่ในการจัดเก็บความจำ โดยจัดหมวดหมู่อย่างชัดเจนให้เป็น “ปีก” ที่แทนบุคคลหรือโปรเจกต์ และเป็นโครงสร้างในระดับต่าง ๆ เช่น ทางเดิน ห้อง และลิ้นชัก เพื่อเก็บต้นฉบับบทสนทนาไว้สำหรับการค้นหาเชิงความหมายในภายหลัง
ทีมพัฒนาอ้างว่า MemPalace ได้คะแนน 100% อันสมบูรณ์แบบในเกณฑ์การประเมินความจำระยะยาว LongMemEval และทำความแม่นยำได้ 96.6% โดยไม่เรียกใช้ API ภายนอกใด ๆ อีกทั้งสามารถรันได้ครบถ้วนบนเครื่องฝั่งผู้ใช้ ไม่จำเป็นต้องสมัครบริการบนคลาวด์ และยังมาพร้อมกับระบบภาษา AAAK ที่อ้างว่าสามารถบีบอัดได้ถึง 30 เท่าแบบไม่สูญเสีย
รูปภาพจาก: GitHub ดาราดังฮอลลีวูด Milla Jovovich สร้าง AI Memory Palace ทำให้สาธารณชนให้ความสนใจ
เพื่อนร่วมวงการและชุมชนต่างตั้งข้อสงสัย วิธีทดสอบและการโปรโมตมีส่วนที่ไม่น่าไว้ใจ
อย่างไรก็ตาม ผลการทดสอบที่อ้างว่าได้คะแนนเต็มใน LongMemEval ไม่นานก็ถูกเพื่อนร่วมวงการตั้งข้อสงสัย
PenfieldLabs ซึ่งเป็นอีกฝ่ายที่พัฒนาระบบหน่วยความจำ AI เช่นกัน ระบุว่า MemPalace อ้างว่าได้คะแนนเต็มในชุดข้อมูล LoCoMo ซึ่งในเชิงคณิตศาสตร์เป็นไปไม่ได้ เพราะคำตอบมาตรฐานของชุดข้อมูลดังกล่าวมี “ข้อผิดพลาดอยู่แล้ว” ถึง 99 รายการ
จากการวิเคราะห์ PenfieldLabs พบว่า ผลคะแนน 100% ของ MemPalace มาจากการตั้งจำนวนครั้งของการค้นหาไว้ที่ 50 ครั้ง แต่จำนวนขั้นตอนสูงสุดของบทสนทนาในชุดข้อมูลทดสอบมีเพียง 32 ครั้งเท่านั้น ซึ่งหมายความว่าระบบเลี่ยงขั้นตอนการค้นหาโดยตรง แล้วส่งข้อมูลทั้งหมดให้โมเดล AI อ่าน
สำหรับคะแนน 100% ใน LongMemEval ทีมพัฒนาถูกพบว่าเน้นแก้ปัญหาเฉพาะที่ผิดพลาดในการพัฒนา 3 ประเด็น โดยเขียนโค้ดสำหรับการแก้ไขแบบเฉพาะทาง จึงมีข้อสงสัยว่าจะมีการโกงเพื่อใช้กับชุดทดสอบ

รูปภาพจาก: Reddit PenfieldLabs ระบุว่า MemPalace อ้างว่าได้คะแนนเต็มในชุดข้อมูล LoCoMo ซึ่งในเชิงคณิตศาสตร์เป็นไปไม่ได้
ผู้ใช้ GitHub ทดลองจริง เกณฑ์มาตรฐานมีส่วนที่ทำให้เข้าใจผิด
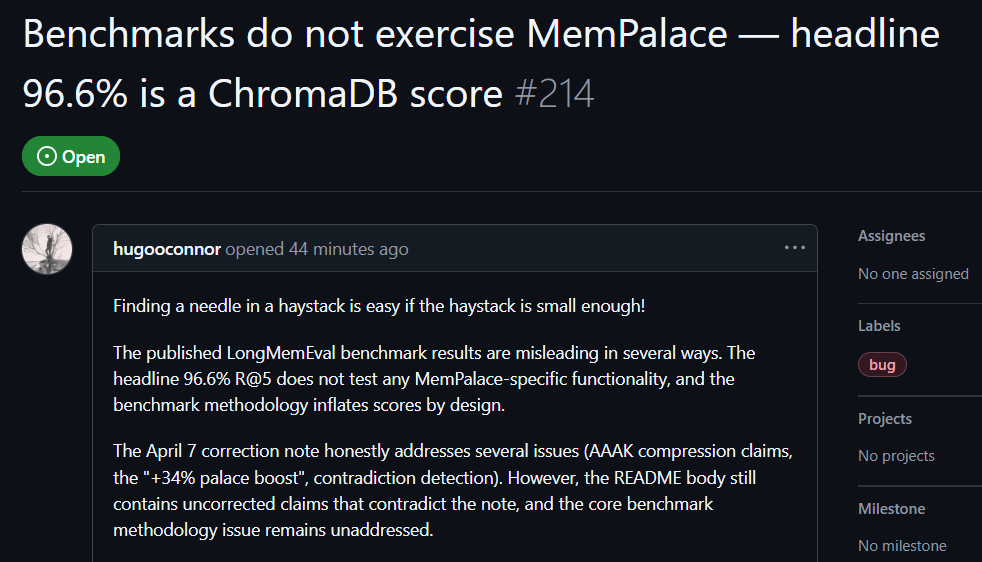
ผู้ใช้ hugooconnor บน GitHub ได้แสดงความคิดเห็นหลังจากทดลองจริงว่า MemPalace อ้างว่ามีความแม่นยำในการค้นหาสูงถึง 96.6% แต่ในความเป็นจริงไม่ได้ใช้โครงสร้าง “AI Memory Palace” ตามที่โปรโมตเอาไว้เลย hugooconnor ระบุว่าการทดสอบของพวกเขาเป็นเพียงการเรียกใช้ฟังก์ชันเริ่มต้นของฐานข้อมูลระดับล่าง ChromaDB เท่านั้น และไม่มีส่วนเกี่ยวข้องกับตรรกะการจัดหมวดหมู่ที่โปรเจกต์เน้น เช่น ปีก ห้อง หรือ ลิ้นชัก
หลังจากทดสอบแล้ว hugooconnor พบว่าเมื่อระบบเปิดใช้งานตรรกะการจัดหมวดหมู่เฉพาะของ memory palace จริง ๆ ผลการค้นหากลับแย่ลง ยกตัวอย่างในโหมดห้อง ความแม่นยำลดลงเหลือ 89.4% และเมื่อเปิดใช้งานเทคนิคการบีบอัด AAAK ความแม่นยำยิ่งลดลงเหลือ 84.2% ทั้งสองค่าต่ำกว่าประสิทธิภาพของฐานข้อมูลค่าเริ่มต้น
hugooconnor ยังวิจารณ์วิธีทดสอบ โดยระบุว่าสภาพแวดล้อมการทดสอบของ MemPalace ตั้งใจย่อ “ขอบเขตการค้นหา” ของคำถามแต่ละข้อให้แคบลงเหลือประมาณ 50 ช่วงบทสนทนา การหาคำตอบในคลังตัวอย่างที่มีขนาดเล็กมากนั้นง่ายเกินไป
หากขยายขอบเขตไปสู่สถานการณ์จริงที่มีมากกว่า 19,000 ช่วงบทสนทนา ความแม่นยำของการค้นหาแบบใช้คีย์เวิร์ดแบบดั้งเดิมจะตกฮวบลงเหลือ 30% แสดงให้เห็นว่าแนวทางทดสอบปัจจุบันของ MemPalace ปกปิด “ปัญหาความยากในการค้นหา” ที่แท้จริงไว้
รูปภาพจาก: GitHub ผู้ใช้ GitHub ทดลองจริง เกณฑ์มาตรฐานของ MemPalace มีส่วนที่ทำให้เข้าใจผิด
ขณะเดียวกัน แม้ทีมพัฒนาจะเผยแพร่คำแถลงการณ์แก้ไขแล้ว โดยยอมรับว่าเทคนิค AAAK ได้รับการพิสูจน์ว่าเป็นการบีบอัดแบบไม่สูญเสีย และสัญญาว่าจะปรับคำอธิบายเอกสารกับการออกแบบระบบตามคำวิจารณ์ที่เข้มงวดจากชุมชน แต่คำอธิบายหลักของโปรเจกต์ยังคงเก็บรักษาข้อกล่าวอ้างที่เกินจริงซึ่งยังไม่ได้รับการแก้ไขหลายรายการ รวมถึงการอ้างว่า “บีบอัดแบบไม่สูญเสีย 30 เท่า” และ “เพิ่มการค้นหา 34%” อีกทั้งแผนภูมิเปรียบเทียบกับคู่แข่งรายอื่นก็ยังขาดแหล่งที่มาอย่างสิ้นเชิง
โค้ดต้นฉบับของ MemPalace เผชิญกับบั๊กหลายประเด็น
เมื่อมีนักพัฒนามากขึ้นเรื่อย ๆ ดาวน์โหลดและทดสอบ ปัจจุบันบนแพลตฟอร์ม GitHub มีรายงานบั๊กจำนวนมากเกี่ยวกับโค้ดต้นฉบับของ MemPalace
ผู้ใช้ cktang88 ได้ระบุข้อบกพร่องร้ายแรงหลายรายการ รวมถึงคำสั่งการบีบอัดที่ใช้งานไม่ได้และทำให้ระบบล่ม ตรรกะการคำนวณจำนวนคำในสรุปผิดพลาด ข้อมูลสถิติที่ขุด “ห้อง” ไม่แม่นยำ และเมื่อมีการเรียกใช้แต่ละครั้ง เซิร์ฟเวอร์จะโหลดข้อมูลที่เกี่ยวข้องทั้งหมดลงในหน่วยความจำ ส่งผลให้มีปัญหาการใช้ทรัพยากรอย่างหนัก
ปัญหาอื่น ๆ ที่ถูกชี้ให้เห็น ยังรวมถึงระบบที่ “ฝัง” ชื่อสมาชิกในครอบครัวของนักพัฒนาไว้ในไฟล์ตั้งค่าเริ่มต้นโดยตรง และมีขีดจำกัดการแสดงแบบบังคับที่ 10,000 รายการข้อมูลเมื่อดูสถานะการค้นหา
สำหรับปัญหาเหล่านี้ ชุมชนโอเพนซอร์สได้เริ่มลงมือแก้ไขอย่างจริงจังแล้ว ผู้ใช้ adv3nt3 ส่งคำขอเพื่อซ่อมแซมหลายรายการ รวมถึงการแก้ไขข้อมูลสถิติของ “ห้อง” การลบชื่อสมาชิกในครอบครัวที่ตั้งไว้ล่วงหน้า และการเลื่อนเวลาเริ่มต้นของการสร้าง knowledge graph ทีมพัฒนาภายหลังยังยอมรับข้อผิดพลาดเหล่านี้ และกำลังแก้ไขปัญหาโค้ดทีละส่วนผ่านความร่วมมือของชุมชน
Vibe Coding ของ Milla Jovovich เท่ดี แต่ไม่เท่ในการทำการตลาด
สำหรับโปรเจกต์ MemPalace บน Hacker News ผู้ใช้ darkhanakh สรุปไว้ว่า: MemPalace ทำให้รู้สึกเหมือน OpenClaw กล่าวคือมีการบิดผลการทดสอบ (benchmark) อย่างจงใจเพื่อให้ดูสมบูรณ์แบบ แล้วค่อยนำไปห่อรวมเป็นการตลาดสำหรับ “ความก้าวหน้าอันยิ่งใหญ่” บางอย่าง
เขามองว่า เทคโนโลยีระดับล่างของ MemPalace อาจน่าสนใจจริง แต่เมื่อวิธีทดสอบมีข้อบกพร่องแบบนี้ และยังเน้นโปรโมตด้วยคำว่า “คะแนนสูงสุดที่เปิดเผยต่อสาธารณะ” ก็ไม่ค่อยเหมาะสมเท่าไรนัก “แต่ถึงอย่างนั้น ผมก็ยังคิดว่า การที่ Milla Jovovich เล่น Vibe Coding เนี่ย เท่ดีอยู่ดีล่ะ”
อ่านเพิ่มเติม:
AI เขียนโค้ดแล้วพัง! แอป “ผู้ล่าผู้ล่าเพื่อเสาะหาของใกล้หมดอายุ” ของร้านสะดวกซื้อ เจอปัญหาความปลอดภัยของข้อมูลส่วนบุคคล บ้านทั้งหลัง GPS เปิดโปงหมด
