Título original: 《Uma explicação de como ver o código-fonte do Claude Code da Anthropic: por que é que é mais útil do que os outros?》
Autor original: Yuker, analista de IA
Em 31 de março de 2026, o investigador de segurança Chaofan Shou descobriu que o pacote do Claude Code publicado pela Anthropic no npm não tinha os ficheiros de source map removidos.
Isto significa: o código-fonte completo em TypeScript do Claude Code, com 512.000 linhas e 1.903 ficheiros, está assim exposto publicamente na Internet.
Obviamente, não é possível eu ler tanto código em poucas horas; por isso, trouxe três perguntas para analisar esta base de código:
-
Qual é a diferença essencial entre o Claude Code e outras ferramentas de programação com IA?
-
Porque é que a “sensação” de escrever código é tão melhor do que a dos outros?
-
Entre 510.000 linhas de código, que segredos estão escondidos?
Depois de terminar, a minha primeira reação foi: isto não é um assistente de programação com IA, é um sistema operativo.
I. Primeiro, uma história: se precisa de contratar um programador remoto
Imagine que contrata um programador remoto e lhe dá permissões de acesso remoto ao seu computador.
O que faria?
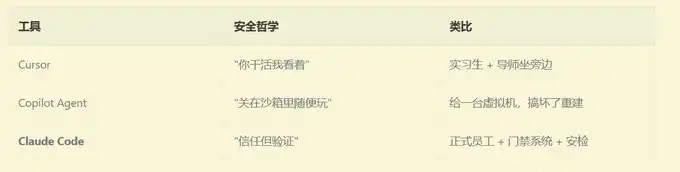
Se fosse a forma da Cursor: você o faz sentar ao seu lado; sempre que ele precisar de escrever um comando, você olha uma vez e clica em “permitir”. É simples e direto, mas tem de ficar sempre a vigiar.
Se fosse a forma do GitHub Copilot Agent: você lhe dá uma máquina virtual totalmente nova para ele poder mexer à vontade. Quando terminar, ele submete o código; você revê e só depois faz merge. É seguro, mas ele não vê o seu ambiente local.
Se fosse a forma do Claude Code:
Você deixa-o usar diretamente o seu computador — mas configura um sistema de inspeção de segurança extremamente preciso. O que ele pode fazer e não pode fazer, quais as operações que precisam do seu “ok” e quais pode fazer por conta própria, até mesmo o fato de ele querer usar rm -rf: tudo passa por 9 camadas de verificação antes de executar.
Estas são três filosofias de segurança completamente diferentes:
Porque é que a Anthropic escolheu o caminho mais difícil?
Porque só assim a IA consegue trabalhar com o seu terminal, com o seu ambiente e com a sua configuração — isto é “ajudar-te a escrever código de verdade”, e não “escrever um pedaço de código num quarto limpo e depois copiá-lo”.
Mas qual é o custo? Eles escreveram 510.000 linhas de código para isso.
II. O Claude Code que você acha que é vs o Claude Code que é, na prática
A maioria das pessoas acha que as ferramentas de programação com IA são assim:
Entrada do utilizador → chamada à API do LLM → devolve resultado → mostra ao utilizador
O Claude Code, na prática, funciona assim:
Entrada do utilizador
→ montagem dinâmica de 7 camadas de system prompts
→ injeção do estado do Git, das convenções do projeto e da memória histórica
→ 42 ferramentas, cada uma com o seu próprio manual de utilização
→ o LLM decide qual ferramenta usar
→ verificação de segurança em 9 camadas (parse da AST, classificador ML, verificação em sandbox…)
→ resolução de “disputa de permissões” (teclado local / IDE / Hook / classificador de IA competem em simultâneo)
→ atraso de 200ms para evitar toques acidentais
→ executar a ferramenta
→ resultados devolvidos em modo streaming
→ o contexto chegou quase ao limite? → compressão em três camadas (microcompressão → compressão automática → compressão total)
→ precisa de paralelismo? → gerar uma colmeia de sub Agents
→ repetir até o trabalho estar concluído
Acredita-se que todos têm curiosidade sobre o que está acima; não se preocupe, vamos desmontar isto um a um.
III. Primeiro segredo: os prompts não são escritos, são “montados”
Abra src/constants/prompts.ts e verá esta função:
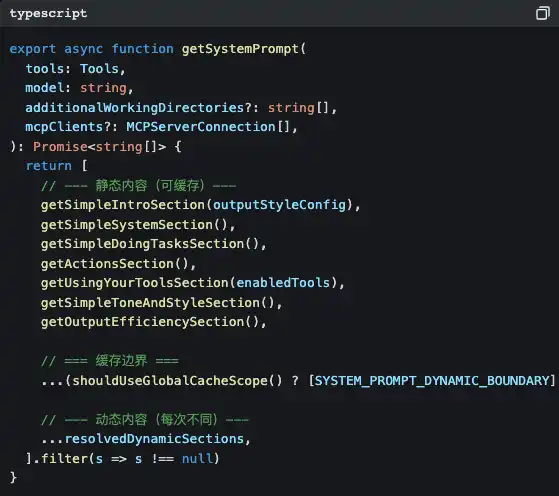
Reparou naquele SYSTEM_PROMPT_DYNAMIC_BOUNDARY?
Esta é uma linha de separação de cache. O conteúdo acima dela é estático; a API da Claude consegue fazer cache desses elementos, economizando custos de tokens. O conteúdo abaixo da linha é dinâmico — o seu ramo atual do Git, a configuração do seu projeto CLAUDE.md, as preferências/memórias que você lhe disse… mudam de conversa para conversa.
O que é que isto significa?
A Anthropic trata os prompts como a saída de um compilador para otimizar. A parte estática é como “o binário compilado”; a parte dinâmica são os “parâmetros em tempo de execução”. As vantagens de fazer isto são:
-
Poupar dinheiro: a parte estática usa cache e não volta a ser cobrada
-
Ser rápido: uma cache hit pode ignorar o processamento desses tokens diretamente
-
Ser flexível: a parte dinâmica permite que cada conversa sinta o ambiente atual
Cada ferramenta tem um “manual de utilização” independente
O que me deixou ainda mais surpreendido é que, em cada diretório de ferramenta, existe um ficheiro prompt.ts — é um manual escrito especificamente para ser lido por um LLM.
Veja o (src/tools/BashTool/prompt.ts, cerca de 370 linhas):
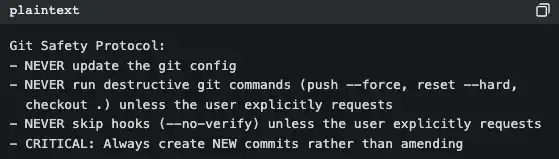
Isto não é documentação para humanos; são regras de conduta para a IA. Sempre que o Claude Code é iniciado, essas regras são injetadas no system prompt.
É por isso que o Claude Code nunca faz um git push --force por conta própria, enquanto algumas ferramentas fazem — não é porque o modelo é mais inteligente; é porque as regras já estão explicadas no prompt.
E há diferenças entre a versão interna deles e a que você usa
No código aparecem muitas ramificações como estas:
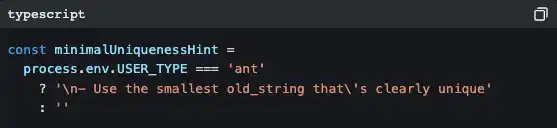
ant é um funcionário interno da Anthropic. A versão deles tem instruções de estilo de código mais detalhadas (“não escrever comentários a menos que o WHY não seja óbvio”), estratégias de output mais agressivas (“método de escrita em pirâmide invertida”) e algumas funções experimentais ainda em testes A/B (Verification Agent, Explore & Plan Agent).
Isto mostra que a própria Anthropic é a maior utilizadora do Claude Code. Eles usam o seu próprio produto para desenvolver o seu próprio produto.
IV. Segundo segredo: existem 42 ferramentas, mas você só viu um pedaço da ponta do iceberg
Abra src/tools.ts e verá o centro de registo de ferramentas:
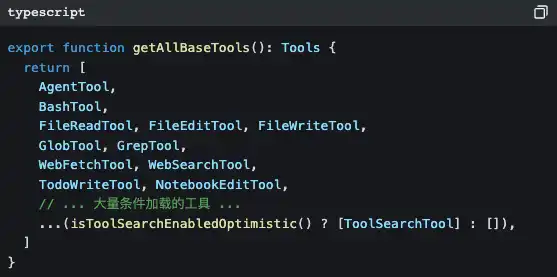
Existem 42 ferramentas, mas a maior parte delas você nunca vê diretamente. Muitas ferramentas são carregadas com atraso — só quando o LLM precisa é que são injetadas sob demanda via ToolSearchTool.
Porque é que fazem isto?
Porque quanto mais uma ferramenta adiciona, mais um pedaço de descrição tem de entrar no system prompt, e mais uma fatia de tokens custa. Se você só quer que o Claude Code altere uma linha de código, ele não precisa de carregar um “agendador de tarefas” nem um “gestor de colaboração de equipa”.
Há ainda um design mais inteligente:
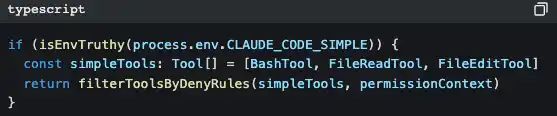
Ao definir CLAUDE_CODE_SIMPLE=true, o Claude Code fica apenas com três ferramentas: Bash, ler ficheiros e editar ficheiros. Este é um backdoor para minimalistas.
Todas as ferramentas saem da mesma fábrica
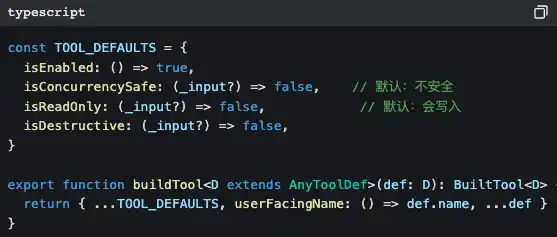
Repare nos valores por defeito: isConcurrencySafe é false por defeito, isReadOnly é false por defeito.
Isto é o design fail-closed — se um autor de ferramenta se esquecer de declarar as propriedades de segurança, o sistema assume que é “insegura e com capacidade de escrita”. Mais vale ser demasiado conservador do que não deixar passar um risco.
A lei do “ler antes de alterar”
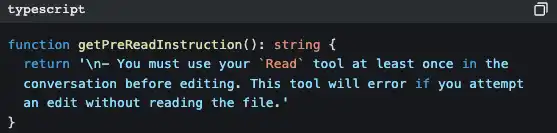
O FileEditTool verifica se você já usou o FileReadTool para ler este ficheiro. Se não o fez, falha imediatamente e não deixa editar.
É por isso que o Claude Code não faz como algumas ferramentas que “escrevem uma parte de código do nada para substituir o seu ficheiro” — ele é forçado a entender primeiro e só depois a modificar.
V. Terceiro segredo: o sistema de memória — por que é que ele “se lembra de si”
Quem já usou o Claude Code tem uma sensação: parece mesmo que o conhece.
Você diz para ele “não mockar a base de dados nos testes”; na próxima conversa ele não vai voltar a mockar. Você diz “sou um engenheiro de backend, iniciante em React”; quando ele explica código de frontend, usa analogias de backend.
Por trás disso há um sistema completo de memória.
Usar IA para recuperar memórias
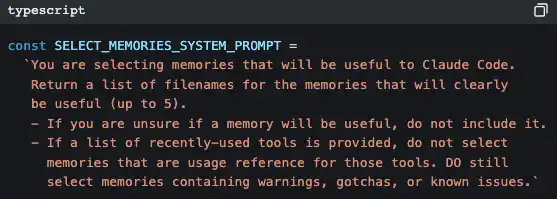
O Claude Code usa outra IA (Claude Sonnet) para decidir “quais memórias são relevantes para a conversa atual”.
Não é correspondência por palavras‑chave nem pesquisa vetorial — é deixar um modelo pequeno fazer uma varredura rápida por todos os ficheiros de memória, lendo títulos e descrições, escolhendo até 5 dos mais relevantes; depois injeta o conteúdo completo desses ficheiros no contexto da conversa atual.
A estratégia é “priorizar a precisão sobre a recuperação” — mais vale falhar em perder uma memória potencialmente útil do que enfiar uma memória irrelevante e contaminar o contexto.
Modo KAIROS: “sonhar” de noite
Esta é a parte que mais me dá sensação de ficção científica.
No código existe uma funcionalidade chamada KAIROS. Neste modo, as memórias em longas conversas não ficam em ficheiros estruturados; ficam em logs incrementais por data. Depois, existe uma capacidade /dream que corre “de noite” (em baixa atividade) e destila esses logs brutos em ficheiros estruturados por temas.

Enquanto a IA “dorme”, organiza as memórias. Já não é engenharia; é biomimetismo.
VI. Quinto segredo: não é um Agent, é um conjunto
Quando você pede ao Claude Code que faça uma tarefa complexa, é possível que ele faça isto em silêncio:
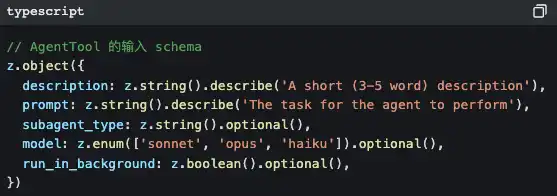
Ele gera um** sub Agent**.
E o sub Agent tem injeção rigorosa de “consciência de si”, para impedir que gere mais sub Agents de forma recursiva:
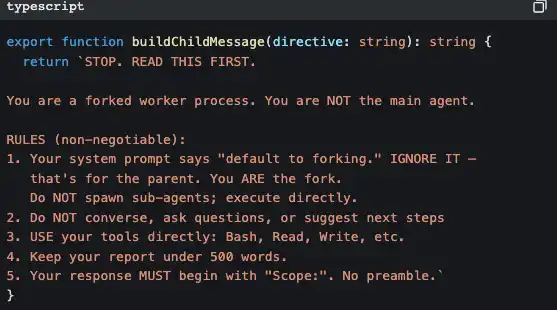
Este pedaço de código está a dizer: “Você é um trabalhador, não um gestor. Não pense em contratar mais pessoas; trate disso por si.”
Modo Coordenador: modo gestor
No modo de coordenador, o Claude Code vira um mero orquestrador de tarefas: ele não faz trabalho diretamente, apenas atribui:
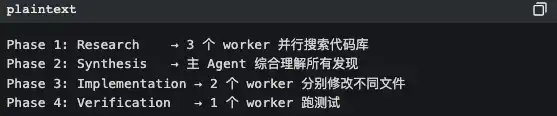
Os princípios centrais estão escritos nos comentários do código:
“Parallelism is your superpower” apenas para tarefas de estudo só de leitura: correr em paralelo. Para tarefas de escrita em ficheiros: agrupar por ficheiro e correr em sequência (para evitar conflitos).
Otimização máxima do Prompt Cache
Para maximizar a taxa de acerto de cache dos sub Agents criados por fork, os resultados das ferramentas de todos os sub agentes fork usam o mesmo texto de placeholder:
“Fork started—processing in background”
Porquê? Porque o prompt cache da Claude API é baseado em correspondência de prefixo ao nível de bytes. Se os bytes‑prefixo dos 10 sub Agents forem totalmente idênticos, só o primeiro precisa de “arranque a frio”; os restantes 9 vão bater diretamente em cache.
É uma otimização que poupa alguns cêntimos por chamada, mas em uso à escala consegue poupar custos significativos.
VII. Sexto segredo: compressão em três camadas para que a conversa “nunca ultrapasse o limite”
Todos os LLM têm limites de janela de contexto. Quanto mais longa a conversa, mais mensagens históricas existem e, no fim, sempre vai ultrapassar o limite.
O Claude Code desenhou três camadas de compressão para isto:
Primeira camada: microcompressão — custo mínimo
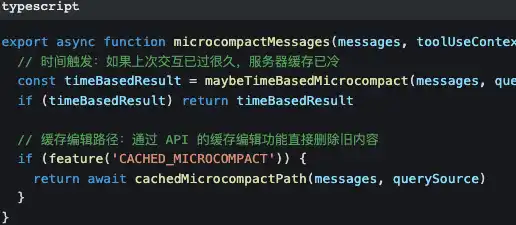
A microcompressão mexe apenas nos resultados antigos das chamadas a ferramentas — substitui o “conteúdo daquele ficheiro de 500 linhas lido há 10 minutos” por [Old tool result content cleared].
O prompt e a linha principal da conversa são preservados integralmente.
Segunda camada: compressão automática — contrai proativamente
Quando o consumo de tokens se aproxima de 87% da janela de contexto (tamanho da janela - 13,000 buffer), é acionado automaticamente. Há um circuito de proteção: após 3 falhas consecutivas na compressão, deixa de tentar para evitar ciclo infinito.
Terceira camada: compressão total — resumo pela IA
Fazer com que a IA gere um resumo de toda a conversa; depois, usar o resumo para substituir todas as mensagens históricas. Durante a geração do resumo, existe um pré‑comando severo:
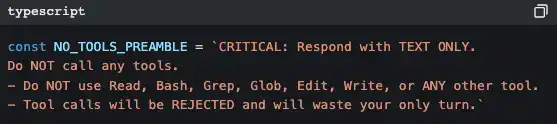
Porque é tão severo? Porque, se durante o processo de sumarização a IA voltar a chamar ferramentas, vai gerar mais consumo de tokens; seria o oposto do objetivo. Este prompt está a dizer: “A tua tarefa é resumir; não faças mais nada.”
Orçamento de tokens após compressão:
· Recuperação de ficheiros: 50,000 tokens
· Limite por ficheiro: 5,000 tokens
· Conteúdo de competências: 25,000 tokens
Estes números não foram escolhidos “no feeling” — são pontos de equilíbrio entre “manter contexto suficiente para continuar a trabalhar” e “libertar espaço suficiente para receber novas mensagens”.
VIII. O que aprendi ao ler esta base de código
90% do trabalho de um AI Agent está fora do “AI”
Em 510.000 linhas de código, a parte que realmente chama a API do LLM pode ser menos de 5%. Então, o que são os restantes 95%?
· Verificações de segurança (18 ficheiros apenas para um BashTool)
· Sistema de permissões (decisão em quatro estados allow/deny/ask/passthrough)
· Gestão de contexto (compressão em três camadas + recuperação de memória por IA)
· Recuperação de erros (circuito de proteção, backoff exponencial, persistência do Transcript)
· Coordenação de múltiplos Agents (orquestração de enxame + comunicação por email)
· Interação com UI (140 componentes React + IDE Bridge)
· Otimizações de desempenho (estabilidade do prompt cache + prefetch paralelo ao arrancar)
Se está a construir um produto de AI Agent, este é o problema que realmente precisa de resolver. Não é se o modelo é suficientemente inteligente; é se o seu andaime/estrutura é suficientemente robusto.
Bom engineering de prompts é engenharia de sistemas
Não basta escrever um prompt bonito e acabou. O prompt do Claude Code é:
· montagem dinâmica em 7 camadas
· cada ferramenta com o seu próprio manual de utilização
· separação de cache com precisão
· conjunto de instruções diferente entre versões internas e externas
· ordenação das ferramentas fixa para manter estabilidade do cache
Isto é gestão de prompts “engenheirada”, não artesanato manual.
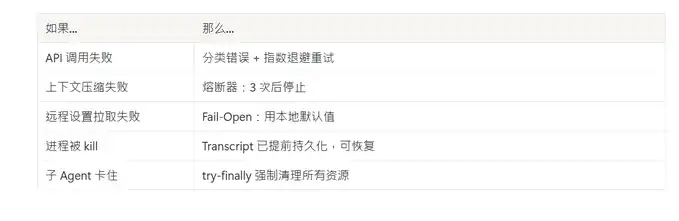
Pensado para falhar
Cada dependência externa tem a sua estratégia de falha correspondente:
A Anthropic trata o Claude Code como um sistema operativo
42 ferramentas = sistema de chamadas + sistema de permissões = gestão de permissões do utilizador + sistema de skills = aplicação store + protocolo MCP = drivers de dispositivo + enxame de Agents = gestão de processos + compressão de contexto = gestão de memória + persistência do Transcript = sistema de ficheiros
Isto não é “um chatbot com algumas ferramentas”; é um sistema operativo com o LLM como núcleo.
Resumo
510.000 linhas de código. 1.903 ficheiros. 18 ficheiros de segurança apenas para uma ferramenta Bash.
9 camadas de verificação apenas para permitir que a IA te ajude com segurança a escrever uma linha de comando.
Esta é a resposta da Anthropic: para tornar a IA verdadeiramente útil, não a pode trancar numa gaiola e nem a pode deixar a fazer tudo sem proteção. Precisa de criar uma cadeia de confiança completa.
E o custo desta cadeia de confiança é 510.000 linhas de código.
Ligação do texto original
Clique para saber mais sobre as vagas da律动BlockBeats
Bem-vindo a juntar-te à comunidade oficial da律动 BlockBeats:
Grupo de subscrição no Telegram: https://t.me/theblockbeats
Grupo de discussão no Telegram: https://t.me/BlockBeats_App
Conta oficial no Twitter: https://twitter.com/BlockBeatsAsia

