Kurz gesagt
- Microsoft hat zwei verschiedene Modi veröffentlicht, die GPT und Claude kombinieren, um die Qualität der KI-Forschung zu verbessern.
- Critique lässt die Modelle zusammenarbeiten, während Council sie parallel arbeiten lässt, wobei ein dritter Prüfer die Abweichungen findet.
- Dieser Zwei-Modell-Workflow behebt Halluzinationen, schwache Zitationen und andere Probleme, die mit KI-Forschung mit nur einem Modell verbunden sind.
Deep-Research-KI war in diesem Jahr eines der heißesten Wettrennen in der Tech-Branche. Google kündigte im Dezember 2024 seinen Forschungsagenten für Gemini an, OpenAI veröffentlichte im Februar 2025 seinen eigenen Forschungsagenten, xAI zog nach, Perplexity legte nach, und Anthropic’s Claude baute sich bei Fachleuten, die detaillierte, zitierte Antworten benötigen, eine treue Anhängerschaft auf, indem es seinen Agenten im April des letzten Jahres einführte.
Jedes Unternehmen versucht, Sie davon zu überzeugen, dass sein einzelnes KI-Modell der klügste Forscher im Raum ist. Microsoft hat gerade gesagt: Warum nur einen auswählen?
Das Unternehmen hat am Montag zwei neue Funktionen für das Researcher-Tool von Copilot angekündigt — genannt Critique und Council — die OpenAI’s GPT und Anthropic’s Claude in Folge an dieselbe Forschungsaufgabe setzen. Das Ergebnis laut Microsofts Tests gegen einen Branchen-Benchmark liegt höher als jedes System, das in diesem Test enthalten war, einschließlich der Modelle von den Top-KI-Unternehmen.
Einführung von Critique, einem neuen Multi-Model-Deep-Research-System in M365 Copilot.
Sie können mehrere Modelle zusammen nutzen, um optimale Antworten und Berichte zu generieren. pic.twitter.com/m4RlQmCKzs
— Satya Nadella (@satyanadella) 30. März 2026
„Critique ist ein neues Multi-Model-Deep-Research-System, das für komplexe Forschungsaufgaben entwickelt wurde. Es trennt die Generierung von der Bewertung und nutzt eine Kombination von Modellen aus Frontier-Labs, einschließlich Anthropic und OpenAI“, erklärt Microsoft. „Ein Modell leitet die Generierungsphase, plant die Aufgabe, iteriert durch Retrieval und erstellt einen ersten Entwurf, während ein zweites Modell sich auf Review und Verfeinerung konzentriert und als erfahrener Prüfer fungiert, bevor der finale Bericht erstellt wird.“
Hier ist das grundlegende Problem, das Critique beheben soll: Heute funktionieren jedes KI-Forschungs-Tool auf die gleiche Weise. Sie stellen eine Frage, ein Modell plant eine Suche, durchforstet Quellen, schreibt einen Bericht und gibt ihn an Sie zurück. Dieses einzelne Modell macht alles, ohne dass jemand seine Arbeit überprüft.
Das kann dazu führen, dass sich einige Halluzinationen einschleichen, einige Fehler in den Zitaten auftreten, gefälschte oder unzutreffende Behauptungen usw.
Critique bricht diesen Workflow in zwei Teile. GPT übernimmt die erste Phase — es plant die Forschung, holt Quellen und schreibt einen ersten Entwurf. Dann tritt Claude als strenger Editor ein und überprüft den Bericht auf faktische Korrektheit, Zitationsqualität und darauf, ob die Antwort tatsächlich das adressiert hat, was gefragt wurde. Erst nach dieser Prüfung erreicht der finale Bericht den Nutzer. Microsoft sagt, dass die Rollen auch irgendwann in die entgegengesetzte Richtung laufen können, wobei Claude den Entwurf erstellt und GPT die Kritik liefert, aber derzeit fängt GPT an.
Im DRACO-Benchmark — einem standardisierten Test, der 100 komplexe Forschungsaufgaben über 10 Domänen hinweg abdeckt, darunter Medizin, Recht und Technologie — erzielte Copilot mit Critique 57.4 Punkte. Anthropics Claude Opus traf allein 42.7. Microsofts kombiniertes System schlägt das nächstbeste Ergebnis um fast 14%.
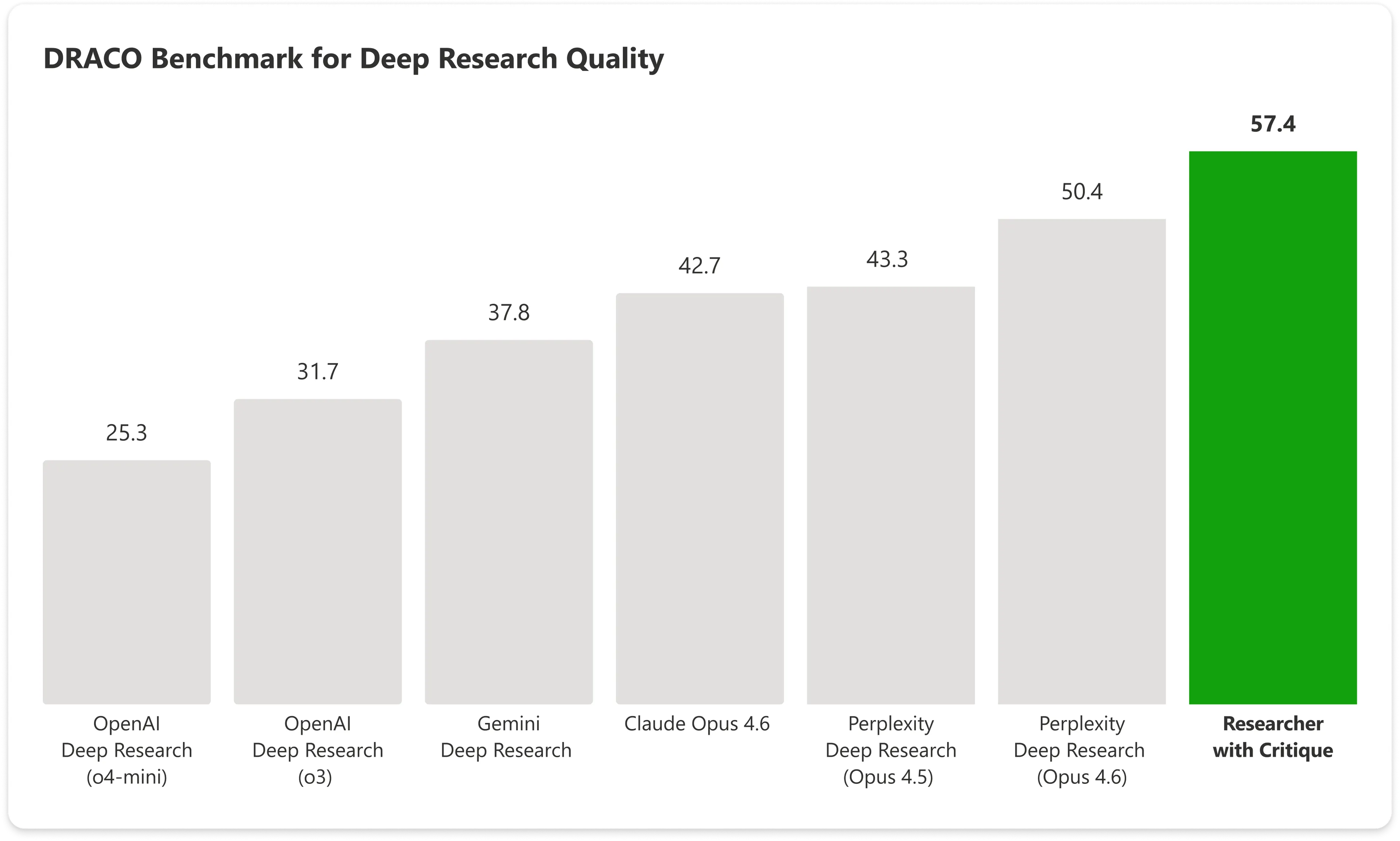
Bild: Microsoft
Die größten Verbesserungen zeigten sich in der Breite der Analyse und in der Qualität der Präsentation, wobei auch die faktische Genauigkeit eine signifikante Steigerung verzeichnete.
Das zweite Feature, Council, verfolgt einen anderen Ansatz für dasselbe Problem. Anstatt dass ein Modell die Arbeit des anderen überprüft, lässt Council GPT und Claude simultan laufen und stellt deren vollständige Berichte nebeneinander. Ein drittes „Richter“-Modell liest dann beide und schreibt eine Zusammenfassung, die erklärt, wo sich die beiden AIs einig waren, wo sie auseinanderliefen und welche einzigartigen Blickwinkel jedes Modell eingefangen hat, die das andere verpasst hat. KI-Forschungs-Tools manuell zu vergleichen war bisher etwas, das Nutzer selbst hätten machen müssen.
Bei Critique arbeiten die Modelle im Wesentlichen zusammen, während sie bei Council gegeneinander antreten.
Critique ist die Standard-Erfahrung in Researcher, während Council verlangt, dass Sie im Auswahlmenü „Model Council“ auswählen, um den Modus mit nebeneinanderliegenden Ergebnissen zu aktivieren. Beide Funktionen sind derzeit für Nutzer verfügbar, die im Frontier-Programm von Microsoft eingeschrieben sind, dem Early-Access-Kanal für die neuesten Fähigkeiten von Copilot. Für eine Microsoft-365-Copilot-Lizenz ($30/user/Monat) ist erforderlich, aber Nutzer müssen außerdem in Frontier eingeschrieben sein, um darauf zugreifen zu können.
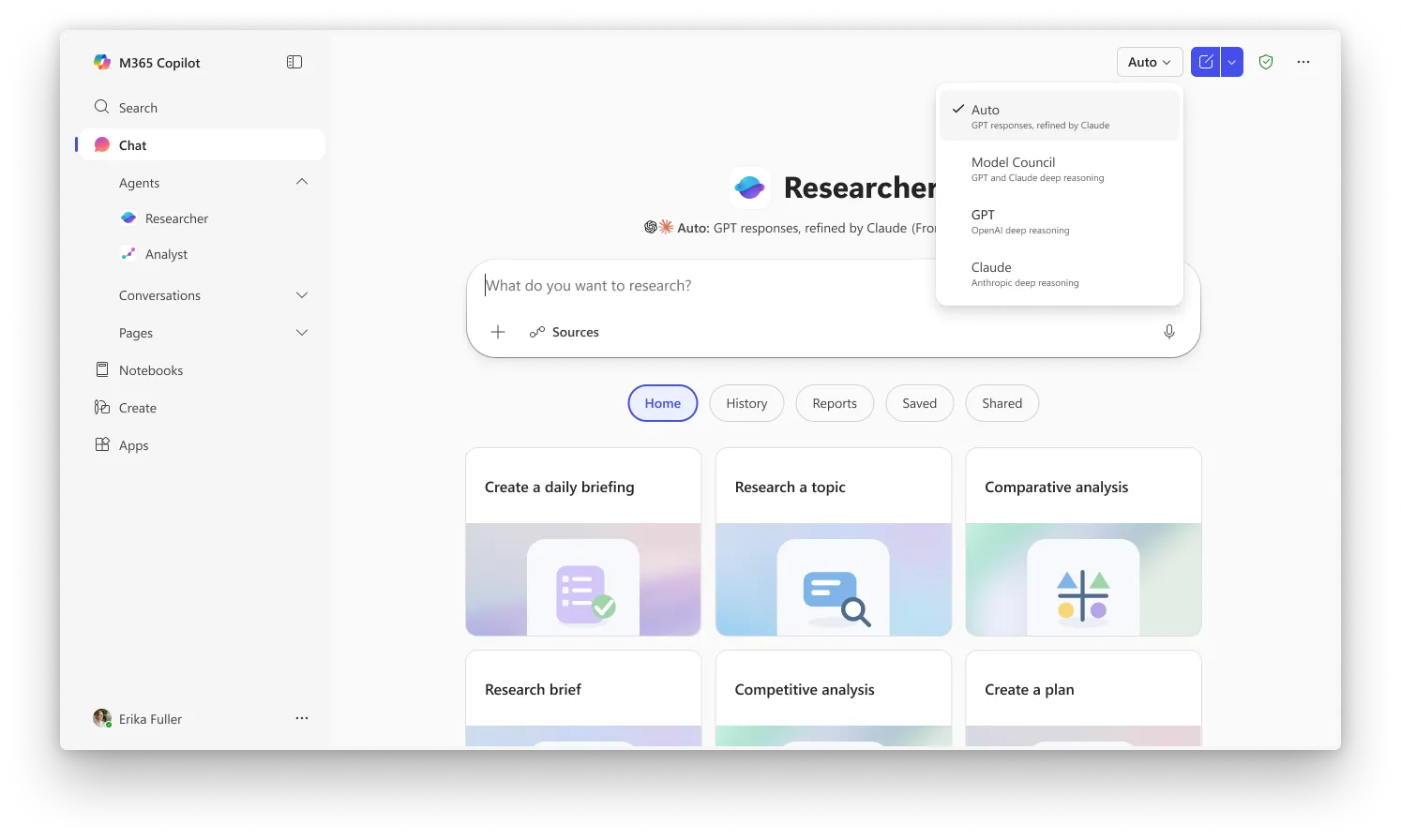
Bild: Microsoft
OpenAI und Microsoft haben eine Partnerschaft im Multi-Milliarden-Dollar-Bereich, aber Microsoft setzt darauf, dass kein einzelnes Modell lange an der Spitze bleibt — und dass der eigentliche Wert in der Orchestrierungsschicht liegt, die Aufgaben dorthin routet, wo die jeweils beste Kombination funktioniert.
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
