Quelle: Wallstreetcn
- März 2026, die NVIDIA GTC 2026 Konferenz eröffnet offiziell, Gründer und CEO Huang Renxun hielt die Keynote.
Auf dieser als „Jahrespilgerfahrt der KI-Branche“ angesehenen Konferenz erläuterte Huang Renxun die Transformation von NVIDIA vom „Chiphersteller“ zum „KI-Infrastruktur- und Fabrikunternehmen“. Angesichts der am meisten beachteten Fragen nach nachhaltiger Leistung und Wachstumspotenzial analysierte Huang die zugrunde liegende Geschäftslogik für zukünftiges Wachstum – die „Token-Fabrik-Ökonomie“.

Sehr optimistische Leistungsprognose: „2027 mindestens 1 Billion US-Dollar Nachfrage“
In den letzten zwei Jahren explodierte die globale Nachfrage nach KI-Rechenleistung exponentiell. Mit der Weiterentwicklung großer Modelle von „Wahrnehmung“ und „Generierung“ zu „Schlussfolgerung“ und „Ausführung (Aufgabenerfüllung)“ steigt der Rechenaufwand rapide. Angesichts der stark beachteten Umsatz- und Bestellobergrenzen gab Huang eine äußerst positive Erwartung ab.
In seiner Rede sagte Huang offen:
Vor einem Jahr sagte ich, wir sehen eine hochsichere Nachfrage von 500 Milliarden US-Dollar, die Blackwell und Rubin bis 2026 abdecken. Jetzt, genau hier und jetzt, sehe ich mindestens 1 Billion US-Dollar Nachfrage bis 2027.

Huang Renxuns Billionen-Erwartung trieb den NVIDIA-Aktienkurs zeitweise um über 4,3 % nach oben.
Darüber hinaus ergänzte er diese Zahl noch:
Ist das realistisch? Das ist das, was ich als Nächstes ansprechen werde. Tatsächlich werden wir sogar eine Angebotsknappheit erleben. Ich bin mir sicher, dass die tatsächliche Rechenbedarf deutlich höher sein wird.
Huang betonte, dass die heutigen NVIDIA-Systeme bereits den Nachweis erbracht haben, die weltweit „kostengünstigste Infrastruktur“ zu sein. Da NVIDIA nahezu alle KI-Modelle in verschiedenen Bereichen betreiben kann, sorgt diese Vielseitigkeit dafür, dass die investierten 1 Billion US-Dollar der Kunden voll genutzt werden können und eine lange Lebensdauer haben.
Derzeit stammen 60 % des NVIDIA-Geschäfts von den fünf größten Cloud-Anbietern, die restlichen 40 % sind breit gestreut in Bereichen wie Souveräne Cloud, Unternehmen, Industrie, Robotik und Edge Computing.
Token-Fabrik-Ökonomie: Leistung pro Watt entscheidet über Geschäftsstrategie
Um die Rationalität dieser 1-Billionen-Demand-Prognose zu erklären, präsentierte Huang den globalen CEOs eine völlig neue Geschäftsphilosophie. Er betonte, dass zukünftige Rechenzentren nicht mehr nur Speicher für Dateien sein werden, sondern „Fabriken“, die Token (die grundlegenden Einheiten der KI-Generierung) produzieren.

Huang unterstrich:
Jede Datenzentrale, jede Fabrik ist per Definition durch die Stromversorgung begrenzt. Eine 1-GW-Fabrik wird niemals zu einer 2-GW-Fabrik. Das sind physikalische und atomare Gesetze. Bei konstanter Leistung gilt: Wer die höchste Token-Durchsatzrate pro Watt erreicht, hat die niedrigsten Produktionskosten.
Huang kategorisierte die zukünftigen KI-Dienste in folgende Geschäftslevel:
Kostenlose Ebene (hoher Durchsatz, niedrige Geschwindigkeit)
Mittlere Ebene (~3 US-Dollar pro Million Token)
Hochwertige Ebene (~6 US-Dollar pro Million Token)
Hochgeschwindigkeits-Ebene (~45 US-Dollar pro Million Token)
Super-Hochgeschwindigkeits-Ebene (~150 US-Dollar pro Million Token)
Er wies darauf hin, dass mit zunehmender Modellgröße und längeren Kontexten KI intelligenter werde, aber die Token-Generierungsrate sinke. Huang sagte:
In dieser Token-Fabrik wird Ihre Durchsatzrate und Token-Generierungsgeschwindigkeit direkt Ihre genauen Einnahmen im nächsten Jahr beeinflussen.
Huang betonte, dass die NVIDIA-Architektur es Kunden ermöglicht, in der kostenlosen Ebene extrem hohe Durchsatzraten zu erzielen, während sie in der wertvollsten Inferenzebene die Leistung um erstaunliche 35-fache steigert.
Vera Rubin erreichte in zwei Jahren 350-fache Beschleunigung, Groq schließt die Lücke bei Hochgeschwindigkeits-Inferenz
Unter den physikalischen Grenzen präsentierte NVIDIA das bislang komplexeste KI-Rechensystem, Vera Rubin. Huang sagte:
Früher zeigte ich einen Hopper-Chip, das war niedlich. Aber bei Vera Rubin denkt man an das gesamte System. In diesem vollständig flüssigkeitsgekühlten System, das alle herkömmlichen Kabel eliminiert, dauert die Installation eines Racks, das früher zwei Tage erforderte, jetzt nur noch zwei Stunden.
Huang wies auf die durchgängige End-to-End-Software- und Hardware-Kooperation hin, die Vera Rubin in einem 1-GW-Datenzentrum beeindruckend beschleunigt:
Innerhalb von nur zwei Jahren haben wir die Token-Generierungsgeschwindigkeit von 22 Millionen auf 700 Millionen erhöht – eine Steigerung um das 350-fache. Das ist mehr als die 1,5-fache Steigerung, die das Moore’sche Gesetz in diesem Zeitraum typischerweise bringt.
Um die Bandbreitenengpässe bei Hochgeschwindigkeits-Inferenz (z.B. 1000 Tokens/sec) zu lösen, präsentierte NVIDIA die endgültige Lösung durch die Integration der übernommenen Firma Groq: asymmetrische, geteilte Inferenz. Huang erklärte:
Diese beiden Prozessoren sind grundlegend unterschiedlich. Groq-Chips verfügen über 500 MB SRAM, Rubin-Chips über 288 GB Speicher.

Huang wies darauf hin, dass NVIDIA durch das Dynamo-Software-System die Phase des „Pre-filling“ (Vorladen) und der „Decoding“-Phase (Entschlüsselung) bei der Vorfüllung auf Vera Rubin auslagert, während die latenzkritische „Decoding“-Phase auf Groq läuft. Er gab auch Empfehlungen für die Rechenkapazitätsplanung:
Wenn Ihre Arbeit hauptsächlich auf hohem Durchsatz basiert, setzen Sie zu 100 % auf Vera Rubin. Wenn Sie große Mengen an hochwertigem Token-Generation benötigen, reservieren Sie 25 % der Rechenkapazität für Groq.
Groq LP30 Chips, die von Samsung gefertigt werden, sind bereits in Massenproduktion und sollen im dritten Quartal ausgeliefert werden. Das erste Vera Rubin-Rack läuft bereits auf Microsoft Azure.
Außerdem präsentierte Huang die erste massenproduzierte optische (CPO) Switch-Switch-Technologie Spectrum X, die den Streit um „Kupfer gegen Licht“ beilegte:
Wir brauchen mehr Kupferkabelkapazitäten, mehr Lichtchips und mehr CPO-Kapazitäten.
Agent: Das Ende des klassischen SaaS, „Jahresgehalt + Token“ wird Standard in Silicon Valley
Neben Hardware-Blockaden widmete Huang viel Raum der Revolution in KI-Software und Ökosystemen, insbesondere dem Aufstieg der Agenten (intelligenten Agenten).
Er bezeichnet das Open-Source-Projekt OpenClaw als „das beliebteste Open-Source-Projekt der Menschheitsgeschichte“, das in nur wenigen Wochen die Leistungen von Linux in den letzten 30 Jahren übertraf. Huang sagte offen, OpenClaw sei im Wesentlichen das „Betriebssystem“ für Agenten-Computer.
Huang erklärte:
Jedes SaaS-Unternehmen wird zu einem AaaS-Unternehmen (Agent-as-a-Service, intelligenter Agent). Um die sichere Implementierung dieser Agenten mit Zugriff auf sensible Daten und Code zu gewährleisten, hat NVIDIA das Enterprise-NeMo Claw Referenzdesign entwickelt, das Strategiemotoren und Datenschutzrouter integriert.
Auch für den normalen Arbeitsplatz ist diese Revolution greifbar. Huang skizzierte die zukünftige Arbeitswelt:
In Zukunft braucht jeder Ingenieur in unserem Unternehmen ein jährliches Token-Budget. Ihr Grundgehalt könnte bei mehreren Hunderttausend Dollar liegen, und ich werde etwa die Hälfte dieses Betrags als Token-Quota bereitstellen, um ihre Effizienz um das Zehnfache zu steigern. Das ist bereits ein neues Einstellungsargument in Silicon Valley: Wie viele Token bietet dein Angebot?
Am Ende seines Vortrags „leakte“ Huang die nächste Generation der Rechenarchitektur Feynman, die erstmals die gemeinsame Skalierung von Kupfer- und CPO-Leitungen ermöglicht. Noch faszinierender ist die Entwicklung eines Weltraum-Datenzentrums-Computers „Vera Rubin Space-1“, der die Vorstellungskraft einer KI-Rechenleistung jenseits der Erde vollständig öffnet.
Der vollständige Text der GTC 2026 Rede von Huang Renxun, maschinell übersetzt:
Moderator: Willkommen auf der Bühne, NVIDIA-Gründer und CEO Huang Renxun.
Huang Renxun, Gründer und CEO:
Willkommen bei GTC. Ich möchte alle daran erinnern, dass dies eine Technologiekonferenz ist. Es freut mich sehr, so viele Menschen früh morgens in der Schlange zu sehen, und ich freue mich, Sie alle hier zu haben.
Auf GTC konzentrieren wir uns auf drei Hauptthemen: Technologie, Plattform und Ökosystem. NVIDIA verfügt derzeit über drei große Plattformen: die CUDA-X Plattform, die Systemplattform und unsere neueste KI-Fabrikplattform.
Bevor wir starten, danke ich unserem Gastgeber für die Warm-up-Session – Sarah Guo von Conviction, Alfred Lin von Sequoia Capital (NVIDIAs erster Risikokapitalgeber) und Gavin Baker, dem ersten bedeutenden institutionellen Investor bei NVIDIA. Diese drei verfügen über tiefgehende Einblicke in die Technologie und haben großen Einfluss auf das gesamte Ökosystem. Natürlich danke ich auch allen heutigen Ehrengästen, die ich persönlich eingeladen habe. Danke an dieses All-Star-Team.
Ich danke auch allen Unternehmen, die heute anwesend sind. NVIDIA ist eine Plattformfirma mit Technologie, Plattformen und einem reichen Ökosystem. Die vertretenen Unternehmen spiegeln fast alle Akteure der Branche im Wert von 100 Billionen US-Dollar wider. Insgesamt 450 Firmen unterstützen diese Veranstaltung, wofür ich herzlich danke.
Diese Konferenz umfasst 1.000 technische Foren und 2.000 Redner, die jeden Aspekt der „Fünf-Schichten-Kuchen“-Architektur der KI abdecken – von Infrastruktur wie Land, Strom und Rechenzentren bis hin zu Chips, Plattformen, Modellen und letztlich den Anwendungen, die die Branche vorantreiben.
CUDA: Zwei Jahrzehnte technologische Grundlage
Der Anfang liegt hier. Dieses Jahr ist das 20. Jubiläum von CUDA.
Seit zwanzig Jahren widmen wir uns der Entwicklung dieser Architektur. CUDA ist eine revolutionäre Erfindung – die SIMT-Technologie (Single Instruction Multiple Threads) erlaubt es Entwicklern, skalaren Code zu schreiben und ihn auf Multithread-Anwendungen zu erweitern, was die Programmierkomplexität deutlich reduziert im Vergleich zu früheren SIMD-Architekturen. Kürzlich haben wir die Tiles-Funktion hinzugefügt, um die Programmierung der Tensor-Kerne (Tensor Cores) zu erleichtern, sowie die mathematischen Strukturen, auf die moderne KI angewiesen ist. Derzeit gibt es Tausende von Tools, Compilern, Frameworks und Bibliotheken für CUDA, und in der Open-Source-Community existieren Hunderttausende von Projekten, die tief in alle Ökosysteme integriert sind.
Dieses Diagramm zeigt die strategische Logik von NVIDIA zu 100 %, ich habe es immer wieder in Präsentationen verwendet. Der schwierigste und zugleich wichtigste Punkt ist die „Installationsbasis“ am unteren Rand des Diagramms. Nach zwanzig Jahren haben wir weltweit Hundertmillionen von GPUs und Rechenzentren, die CUDA ausführen.
Unsere GPUs decken alle Cloud-Plattformen ab und bedienen nahezu alle Computerhersteller und Branchen. Das enorme Volumen an CUDA-Installationen ist die treibende Kraft dieses Wachstums. Die Installationsbasis zieht Entwickler an, die neue Algorithmen entwickeln und Durchbrüche erzielen. Diese Durchbrüche schaffen neue Märkte, die wiederum neue Ökosysteme anziehen und mehr Unternehmen zur Teilnahme bewegen, was die Installationsbasis weiter vergrößert – dieser Kreislauf beschleunigt sich ständig.
Die Download-Zahlen der NVIDIA-Bibliotheken wachsen rasant, die Größenordnung ist enorm und die Wachstumsrate steigt stetig. Dieser Kreislauf ermöglicht es unserer Rechenplattform, eine Vielzahl von Anwendungen und Innovationen zu tragen.
Noch wichtiger ist, dass diese Infrastruktur eine extrem lange Nutzungsdauer hat. Der Grund ist offensichtlich: Anwendungen, die auf NVIDIA CUDA laufen, sind äußerst vielfältig und decken alle Phasen des KI-Lebenszyklus, verschiedenste Datenverarbeitungsplattformen und wissenschaftliche Solver ab. Sobald eine NVIDIA-GPU installiert ist, ist ihr tatsächlicher Nutzen sehr hoch. Das erklärt, warum die Cloud-Preise für unsere Ampere-Architektur-GPUs vor sechs Jahren sogar gestiegen sind.
All dies basiert auf der enormen Installationsbasis, dem sich beschleunigenden Kreislauf und einem breiten Entwickler-Ökosystem. Wenn diese Faktoren zusammenwirken und wir unsere Software kontinuierlich aktualisieren, sinken die Rechenkosten stetig. Beschleunigtes Rechnen verbessert die Anwendungsleistung erheblich, und durch langfristige Wartung und Software-Iterationen profitieren Nutzer nicht nur von anfänglichen Leistungssprüngen, sondern auch von dauerhaft sinkenden Kosten. Wir sind bereit, jede NVIDIA-GPU weltweit langfristig zu unterstützen, weil sie architektonisch vollständig kompatibel sind.
Unser Grund: Die enorme Installationsbasis – jede Optimierung kommt Millionen Nutzern zugute. Dieses dynamische Zusammenspiel sorgt dafür, dass NVIDIA-Architekturen ihre Reichweite erweitern, das Wachstum beschleunigen und die Rechenkosten senken, was wiederum neues Wachstum stimuliert. CUDA ist das Herzstück all dessen.
Von GeForce zu CUDA: 25 Jahre Entwicklung
Unsere Reise mit CUDA begann tatsächlich vor 25 Jahren.
Viele hier sind mit GeForce aufgewachsen. GeForce ist NVIDIAs erfolgreichstes Marketingprojekt. Wir haben die zukünftigen Kunden schon dann aufgebaut, als sie sich noch kein Produkt leisten konnten – ihre Eltern wurden die ersten NVIDIA-Nutzer, kauften Jahr für Jahr unsere Produkte, bis sie selbst zu hervorragenden Informatikern und echten Kunden und Entwicklern wurden.
Das ist das Fundament, das vor 25 Jahren mit GeForce gelegt wurde. Vor 25 Jahren erfanden wir die programmierbaren Shader – eine offensichtliche, aber tiefgreifende Innovation, die die Beschleuniger programmierbar machte, und die erste programmierbare Beschleuniger-Architektur überhaupt: den Pixel-Shader. Fünf Jahre später schufen wir CUDA – eine unserer wichtigsten Investitionen aller Zeiten. Damals waren unsere finanziellen Mittel begrenzt, aber wir setzten den Großteil unseres Gewinns ein, um CUDA von GeForce auf jeden Computer zu bringen. Unser Glaube an das Potenzial war stark. Anfangs war es schwierig, aber wir hielten 13 Generationen und 20 Jahre lang an dieser Überzeugung fest. Heute ist CUDA überall.
Der Pixel-Shader trieb die Revolution bei GeForce voran. Vor etwa acht Jahren brachten wir RTX auf den Markt – eine umfassende Innovation für die moderne Computergrafik. GeForce brachte CUDA in die Welt, was dazu führte, dass Forscher wie Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, Andrew Ng und viele andere erkannten, dass GPUs die besten Beschleuniger für Deep Learning sind, und so den KI-Boom vor zehn Jahren entfachten.
Vor zehn Jahren beschlossen wir, programmierbares Shading mit zwei neuen Konzepten zu verbinden: Erstens Hardware-basiertes Ray Tracing, eine technisch äußerst anspruchsvolle Innovation; zweitens eine visionäre Idee – vor etwa zehn Jahren sahen wir voraus, dass KI die Computergrafik grundlegend verändern würde. Wie GeForce KI in die Welt brachte, wird KI heute die Art und Weise, wie Computergrafik umgesetzt wird, neu gestalten.
Heute möchte ich die Zukunft vorstellen. Es ist unsere nächste Generation der Grafiktechnologie, genannt Neural Rendering – die tiefe Verschmelzung von 3D-Grafik und KI. Das ist DLSS 5, schauen Sie es an.
Neural Rendering: Die Verbindung von strukturierter Daten und generativer KI
Ist das atemberaubend? Die Computergrafik erlebt eine Renaissance.
Was haben wir gemacht? Wir verbinden kontrollierbare 3D-Grafik (die reale Grundlage virtueller Welten) mit strukturierten Daten, integriert in generative KI und probabilistische Berechnungen. Ein vollständig deterministischer Ansatz, der andere probabilistisch, aber hochrealistisch – wir verschmelzen beide Konzepte, um präzise kontrollierte Inhalte in Echtzeit zu generieren. Das Ergebnis: Inhalte, die sowohl schön als auch vollständig steuerbar sind.
Die Fusion von strukturierter Information und generativer KI wird in zahlreichen Branchen immer wieder auftreten. Strukturierte Daten sind die Basis für vertrauenswürdige KI.
Plattformen für beschleunigte Verarbeitung strukturierter und unstrukturierter Daten
Hier eine technische Übersicht.
Strukturierte Daten – bekannt durch SQL, Spark, Pandas, Velox sowie Plattformen wie Snowflake, Databricks, Amazon EMR, Azure Fabric, Google BigQuery – werden in Data Frames verarbeitet. Diese Data Frames sind wie riesige Tabellen, die alle geschäftlichen Informationen enthalten und die Grundwahrheit (Ground Truth) für Unternehmen darstellen.
Im KI-Zeitalter brauchen wir, dass KI diese strukturierten Daten nutzt und sie extrem beschleunigt. Früher diente die Beschleunigung der strukturierten Datenverarbeitung der Effizienzsteigerung von Unternehmen. Zukünftig wird KI diese Daten mit Geschwindigkeiten nutzen, die den Menschen bei weitem übertreffen, und KI-Agenten werden große Mengen an strukturierten Datenbanken abfragen.
Bei unstrukturierten Daten, wie Vektor-Datenbanken, PDFs, Videos, Audios, handelt es sich um die meisten Daten der Welt – etwa 90 % der jährlich erzeugten Daten sind unstrukturiert. Früher konnten wir diese Daten kaum nutzen: Wir lasen sie, speicherten sie in Dateisystemen, mehr nicht. Wir konnten sie nicht abfragen, nur schwer durchsuchen, weil unstrukturierte Daten keine einfachen Indexierungsmöglichkeiten haben und ihr Inhalt und Kontext verstanden werden müssen. Jetzt kann KI das – durch multimodale Wahrnehmung und Verständnis. KI liest PDFs, versteht deren Bedeutung und integriert sie in durchsuchbare Strukturen.
Dafür hat NVIDIA zwei Basiskomponenten entwickelt:
- cuDF: für beschleunigte Verarbeitung von Data Frames und strukturierten Daten
- cuVS: für Vektor-Storage, semantische Daten und unstrukturierte KI-Daten
Diese beiden Plattformen werden in Zukunft eine der wichtigsten Basistechnologien sein.
Heute kündigen wir Kooperationen mit mehreren Unternehmen an. IBM – Erfinder der SQL-Sprache – nutzt cuDF zur Beschleunigung seiner WatsonX Data Plattform. Dell hat gemeinsam mit uns die Dell AI Data Platform entwickelt, die cuDF und cuVS integriert und in realen NTT Data-Projekten erhebliche Leistungssteigerungen erzielt. Google Cloud beschleunigt nicht nur Vertex AI, sondern auch BigQuery, und arbeitet mit Snapchat zusammen, um die Rechenkosten um fast 80 % zu senken.
Beschleunigtes Rechnen bringt Vorteile in drei Dimensionen: Geschwindigkeit, Skalierung und Kosten. Das folgt der Logik des Moore’schen Gesetzes – durch Beschleunigung der Rechenleistung werden Leistungssteigerungen erzielt, während die Kosten kontinuierlich sinken.
NVIDIA hat eine Plattform für beschleunigtes Rechnen aufgebaut, die viele Bibliotheken vereint: RTX, cuDF, cuVS usw. Diese Bibliotheken sind die Kernassets des Unternehmens und ermöglichen es, Rechenplattformen in verschiedenen Branchen praktisch nutzbar zu machen.
Enge Zusammenarbeit mit Cloud-Anbietern
Kooperationen mit führenden Cloud-Anbietern:
Google Cloud: Wir beschleunigen Vertex AI und BigQuery, integrieren tief mit JAX/XLA, sind der einzige Anbieter, der auf PyTorch und JAX/XLA gleichermaßen beschleunigt. Wir bringen Kunden wie Base10, CrowdStrike, Puma, Salesforce in das Google-Ökosystem.
AWS: Wir beschleunigen EMR, SageMaker und Bedrock, sind tief integriert. Besonders freue ich mich, dass wir OpenAI auf AWS bringen – das wird die Nutzung von AWS deutlich steigern und OpenAI bei regionalen Deployments und Rechenkapazitäten unterstützen.
Microsoft Azure: Unser 100-PFLOPS-Supercomputer auf Azure ist der erste, der dort installiert wurde, und bildet die Grundlage für die Zusammenarbeit mit OpenAI. Wir beschleunigen Azure Cloud-Services und AI Foundry, erweitern Azure-Regionen und arbeiten eng mit Bing zusammen. Besonders hervorzuheben ist unsere „Confidential Computing“-Fähigkeit – NVIDIA-GPUs, die den Schutz der Nutzerdaten und Modelle auch für Betreiber garantieren. Diese GPUs sind die ersten weltweit, die Confidential Computing unterstützen, und ermöglichen den sicheren Einsatz von OpenAI- und Anthropic-Modellen in Cloud-Umgebungen weltweit. Beispiel: Wir beschleunigen die EDA- und CAD-Workflows von Synopsys und setzen sie auf Microsoft Azure ein.
Oracle: Wir sind der erste KI-Kunde von Oracle. Ich bin stolz, Oracle erstmals das Konzept der KI-Cloud erklärt zu haben. Seitdem wächst Oracle rasant, und wir haben Partnerschaften mit Cohere, Fireworks, OpenAI und anderen aufgebaut.
CoreWeave: Die weltweit erste KI-native Cloud, speziell für GPU-Hosting und KI-Cloud-Dienste, mit großem Kundenstamm und starkem Wachstum.
Palantir + Dell: Gemeinsam haben wir eine neue KI-Plattform entwickelt, basierend auf Palantirs Ontology Platform und KI-Frameworks, die eine vollständige lokale Deployment-Option in jeder Region und in jeder Isolationsumgebung bietet – von Datenverarbeitung (Vektorisierung oder Strukturierung) bis hin zu vollständiger beschleunigter KI.
NVIDIA hat mit globalen Cloud-Anbietern eine spezielle Kooperationsform etabliert – wir bringen Kunden in die Cloud, was ein Win-Win-Ökosystem schafft.
Vertikale Integration, horizontale Offenheit: NVIDIAs Kernstrategie
NVIDIA ist das weltweit erste vertikal integrierte und gleichzeitig offene Unternehmen.
Dieses Modell ist notwendig, weil beschleunigtes Rechnen kein Chip- oder Systemproblem ist, sondern eine Anwendungsbeschleunigung. CPUs lassen den Computer insgesamt schneller laufen, aber dieser Weg ist an seine Grenzen gestoßen. Zukünftig wird nur durch anwendungsspezifische oder domänenspezifische Beschleunigung kontinuierlich Leistung steigen und Kosten sinken.
Deshalb ist es für NVIDIA unerlässlich, in eine Vielzahl von Bibliotheken, Branchen und vertikalen Märkten zu investieren. Wir sind ein vertikal integriertes Rechenunternehmen, es gibt keinen anderen Weg. Wir müssen Anwendungen verstehen, Branchen durchdringen, Algorithmen tief erfassen und sie in jedem Szenario – Rechenzentrum, Cloud, lokal, Edge oder Robotik – einsetzen können.
Gleichzeitig bleiben wir offen für Partnerschaften, um unsere Technologie in Plattformen anderer zu integrieren, damit alle von beschleunigtem Rechnen profitieren.
Die Teilnehmerstruktur dieser GTC spiegelt das wider. Der größte Anteil kommt aus dem Finanzdienstleistungssektor – hier sind die Entwickler, nicht die Händler. Unser Ökosystem umfasst die gesamte Lieferkette. Ob Unternehmen seit 50, 70 oder 150 Jahren bestehen, sie hatten im letzten Jahr ihre besten Jahre. Wir stehen am Anfang einer sehr, sehr bedeutenden Entwicklung.
CUDA-X: Beschleunigungs-Engines für alle Branchen
In allen vertikalen Bereichen ist NVIDIA tief vertreten:
- Autonomes Fahren: breit gefächert, weitreichend
- Finanzdienstleistungen: Quant-Investitionen wandeln sich von manuellen Features zu Deep-Learning-gestützten Supercomputern, es ist die „Transformer-Ära“
- Medizin: erlebt sein eigenes „ChatGPT“-Moment, mit KI-gestützter Medikamentenentwicklung, KI-Agenten für Diagnosen, medizinischem Kundenservice
- Industrie: weltweite Bauwelle, KI-Fabriken, Chip- und Rechenzentrumsfabriken entstehen
- Unterhaltung & Gaming: Echtzeit-KI-Plattformen für Übersetzung, Livestreams, Spielinteraktion und intelligente Shopping-Agenten
- Robotik: über 10 Jahre Erfahrung, drei große Architekturen (Trainingsrechner, Simulationsrechner, Onboard-Rechner), 110 Robotermodelle auf der Messe
- Telekommunikation: ein Branchenvolumen von ca. 2 Billionen US-Dollar, Basisstationen entwickeln sich von reinen Kommunikationsknoten zu KI-Infrastrukturplattformen, genannt Aerial, mit Partnerschaften u.a. mit Nokia, T-Mobile
Alle diese Bereiche basieren auf den Kernbibliotheken von CUDA-X – das Fundament von NVIDIA als Algorithmus-Unternehmen. Diese Bibliotheken sind die wichtigsten Assets, um in den jeweiligen Branchen echten Mehrwert zu schaffen.
Eine der wichtigsten Bibliotheken ist cuDNN (CUDA Deep Neural Network Library), die die KI-Revolution maßgeblich vorangetrieb und den modernen KI-Boom ausgelöst hat.
(Präsentationsvideo zu CUDA-X abspielen)
Was Sie gerade gesehen haben, ist Simulation – inklusive physikalischer Solver, KI-physikalischer Modelle und physikalischer KI-Roboter. Alles simuliert, keine manuelle Animation oder Gelenkbindung. Das ist die Kernkompetenz von NVIDIA: Durch tiefes Verständnis der Algorithmen und organische Verbindung mit der Rechenplattform diese Chancen zu erschließen.
KI-native Unternehmen und die neue Rechenära
Sie haben die Branchenriesen wie Walmart, L’Oréal, JPMorgan, Roche, Toyota gesehen, aber auch viele unbekannte Firmen – wir nennen sie KI-native Unternehmen. Diese Liste ist enorm, darunter OpenAI, Anthropic und viele Start-ups in verschiedenen vertikalen Bereichen.
In den letzten zwei Jahren hat diese Branche einen enormen Aufschwung erlebt. Die Risikokapitalinvestitionen in Start-ups erreichten 150 Milliarden US-Dollar – Rekord in der Menschheitsgeschichte. Noch wichtiger: Die einzelnen Investitionen stiegen erstmals von wenigen Millionen auf mehrere Hundert Millionen oder sogar mehrere Milliarden US-Dollar. Der Grund: Es ist das erste Mal, dass jedes dieser Unternehmen enorme Rechenressourcen und Token-Mengen benötigt. Diese Branche schafft, generiert und wertet Token auf – von Organisationen wie Anthropic, OpenAI.
Wie die PC-Revolution, die Internet-Revolution und die Mobile-Cloud-Revolution werden auch diese Plattform-Revolution eine Reihe bahnbrechender Unternehmen hervorbringen, die die Welt maßgeblich prägen.
Drei historische Durchbrüche, die alles vorantreiben
Was ist in den letzten zwei Jahren passiert? Drei große Ereignisse.
Erstens: ChatGPT, das Tor zur generativen KI (Ende 2022 bis 2023)
Es kann nicht nur wahrnehmen und verstehen, sondern auch einzigartige Inhalte generieren. Ich zeigte die Verschmelzung von generativer KI und Computergrafik. Generative KI verändert die Art der Berechnung grundlegend – von Retrieval zu Generierung, was die Architektur, Deployment-Methoden und die gesamte Bedeutung tiefgreifend beeinflusst.
Zweitens: Reasoning AI, repräsentiert durch o1
Schlussfolgerungsfähigkeit ermöglicht es KI, sich selbst zu reflektieren, zu planen und Probleme zu zerlegen – komplexe Fragen in verarbeitbare Schritte zu zerlegen. o1 macht generative KI vertrauenswürdig, sie kann auf echte Informationen basieren. Dafür wächst die Eingabemenge an Tokens im Kontext und die Ausgaben zum Nachdenken erheblich, was die Rechenleistung deutlich erhöht.
Drittens: Claude Code, das erste intelligente Agentenmodell
Es kann Dateien lesen, Code schreiben, kompilieren, testen, evaluieren und iterieren. Claude Code revolutioniert die Softwareentwicklung – alle NVIDIA-Ingenieure nutzen mindestens eine der KI-Tools Claude Code, Codex oder Cursor. Kein Softwareingenieur arbeitet ohne KI-Unterstützung.
Das ist ein Wendepunkt: Statt nur zu fragen „Was ist das, wo ist es, wie macht man es?“, lässt man die KI „erstellen, ausführen, bauen“ – sie nutzt aktiv Werkzeuge, liest Dateien, zerlegt Probleme und handelt. KI geht vom Wahrnehmen über das Generieren bis zum Schlussfolgern und kann jetzt tatsächlich Aufgaben erledigen.
In den letzten zwei Jahren ist die Rechenleistung für Schlussfolgerungen um etwa 10.000-fach gestiegen, die Nutzung um etwa 100-fach. Ich bin überzeugt: Die letzten zwei Jahre haben die Rechenanforderungen um das 1.000.000-fache steigen lassen – das ist die gemeinsame Erfahrung aller, von OpenAI, Anthropic und anderen. Mehr Rechenkapazität bedeutet mehr Token, mehr Einnahmen, intelligenteres KI. Der Wendepunkt bei Schlussfolgerungen ist erreicht.
Die Ära der trillionen-dollar KI-Infrastruktur
Letztes Jahr sagte ich hier, wir seien hoch zuversichtlich, dass die Nachfrage und Bestellungen für Blackwell und Rubin bis 2026 bei etwa 500 Milliarden US-Dollar liegen. Heute, ein Jahr später bei GTC, sage ich: Für 2027 sehe ich mindestens 1 Billion US-Dollar, und ich bin sicher, die tatsächliche Nachfrage wird noch deutlich höher sein.
2025: NVIDIA’s Jahr der Schlussfolgerung
2025 ist das Jahr der Inferenz bei NVIDIA. Wir wollen sicherstellen, dass wir in allen Phasen des KI-Lebenszyklus – vom Training bis zur Nachbearbeitung – exzellent bleiben, damit die investierte Infrastruktur dauerhaft effizient arbeitet und die Lebensdauer möglichst lang ist.
Gleichzeitig sind Anthropic und Meta offiziell bei NVIDIA eingestiegen, was ein Drittel der weltweiten KI-Rechenleistung ausmacht. Open-Source-Modelle nähern sich der Spitze, überall präsent.
NVIDIA ist derzeit der einzige Anbieter, der alle KI-Bereiche – Sprache, Biologie, Computergrafik, Computer Vision, Sprachverarbeitung, Proteine, Chemie, Robotik – auf einer Plattform betreiben kann, egal ob Edge oder Cloud, egal welche Sprache. Diese universelle Architektur macht NVIDIA zum kostengünstigsten und vertrauenswürdigsten Anbieter.
Derzeit stammen 60 % unseres Geschäfts aus den fünf größten Cloud-Anbietern, die restlichen 40 % sind in regionalen Clouds, Souveränen Clouds, Unternehmen, Industrie, Robotik und Edge verteilt. Die breite Abdeckung der KI ist die Stärke – das ist eine fundamentale Plattformrevolution.
Grace Blackwell und NVLink 72: Radikale Architekturinnovation
Während die Hopper-Architektur noch in Hochform ist, haben wir beschlossen, das System komplett neu zu konzipieren: NVLink wurde von 8 auf 72 Kanäle erweitert, um das Rechen- und Speichersystem neu zu strukturieren. Grace Blackwell NVLink 72 ist eine große technische Wette, die alle Partner vor Herausforderungen stellt – an dieser Stelle meinen Dank an alle.
Gleichzeitig haben wir den NVFP4 eingeführt – eine völlig neue Art von Tensor-Kernen und Recheneinheiten. Wir haben bewiesen, dass NVFP4 bei Inferenz ohne Genauigkeitsverlust enorme Leistungs- und Energieeffizienzsteigerungen bringt, und es ist auch für das Training geeignet. Zudem sind neue Algorithmen wie Dynamo und TensorRT-LLM erschienen, und wir haben Milliarden in eine Supercomputer-Infrastruktur investiert, den DGX Cloud.
Das Ergebnis: Unsere Inferenzleistung ist beeindruckend. Daten von Semi Analysis – der bislang umfassendsten KI-Inferenz-Leistungsbewertung – zeigen, dass NVIDIA bei Token pro Watt und Tokenkosten führend ist. Während das Moore’sche Gesetz für den H200 nur eine 1,5-fache Leistungssteigerung bringt, erreichen wir 35-fache. Dylan Patel von Semi Analysis sagte sogar: „Huang hat konserviert, es sind eigentlich 50-fach.“ Das stimmt.
Ich zitiere ihn: „Jensen hat die Zahlen geschätzt.“
NVIDIA’s Token-Kosten sind weltweit die niedrigsten. Der Grund: extrem koordiniertes Design (Extreme Co-design).
Beispiel Fireworks: Vor der Software- und Algorithmus-Optimierung lag die durchschnittliche Token-Geschwindigkeit bei ca. 700/sec; nach Optimierung bei fast 5.000/sec – eine Steigerung um den Faktor 7. Das zeigt die Kraft des extremen Co-designs.
KI-Fabrik: Vom Rechenzentrum zur Token-Fabrik
Früher war das Rechenzentrum nur Speicherort für Dateien, heute ist es eine Token-Fabrik. Jede Cloud, jedes KI-Unternehmen wird künftig die „Token-Fabrik-Effizienz“ als zentrale Kennzahl nutzen.
Mein Kernargument:
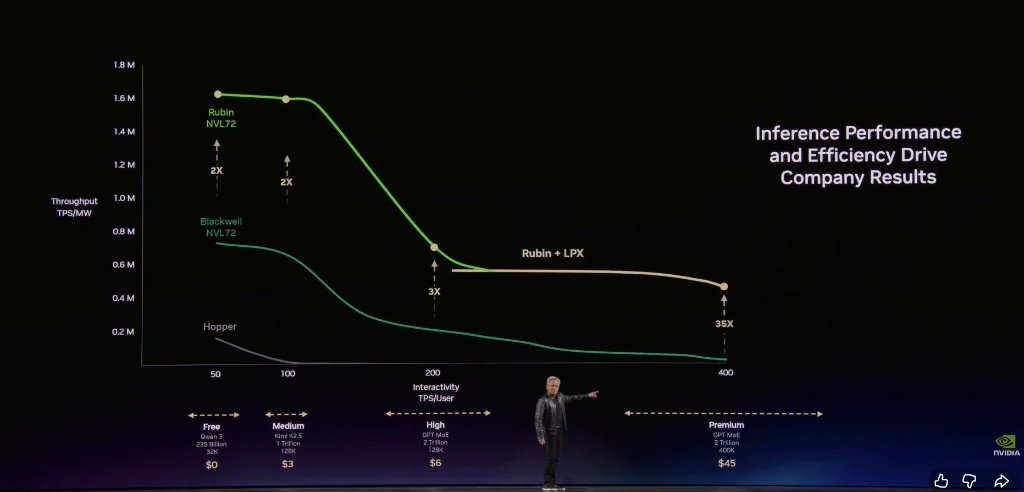
- Vertikale Achse: Durchsatz (Throughput) – Anzahl der generierten Token pro Sekunde bei konstanter Leistung
- Horizontale Achse: Reaktionsgeschwindigkeit (Token Speed) – Antwortzeit pro Inferenz, je schneller, desto größere Modelle und längere Kontexte, desto intelligenter die KI
Token sind die neue Rohware. Wenn sie reifen, werden sie hierarchisch bepreist:
- Kostenlose Ebene (hoher Durchsatz, niedrige Geschwindigkeit)
- Mittlere Ebene (~3 US-Dollar pro Million Token)
- Hochwertige Ebene (~6 US-Dollar pro Million Token)
- Hochgeschwindigkeits-Ebene (~45 US-Dollar pro Million Token)
- Super-Hochgeschwindigkeits-Ebene (~150 US-Dollar pro Million Token)
Im Vergleich zu Hopper hat Grace Blackwell bei der höchsten Wertschöpfungsebene den Durchsatz um das 35-fache erhöht und eine völlig neue Ebene eingeführt. Bei einer vereinfachten Modellrechnung, bei der 25 % der Leistung auf die vier Ebenen verteilt werden, kann Grace Blackwell im Vergleich zu Hopper das Fünffache an Einnahmen generieren.
Vera Rubin: Die nächste Generation der KI-Rechensysteme
(Vorführungsvideo Vera Rubin System)
Vera Rubin ist ein vollständig optimiertes End-to-End-System, speziell für Agenten (Agentic) ausgelegt:
- Rechenkern für große Sprachmodelle: NVLink 72 GPU Cluster, für Pre-filling und KV-Cache
- Neue Vera CPU: für extrem hohe Single-Thread-Leistung, mit LPDDR5-Speicher, höchst energieeffizient, weltweit erster Einsatz von LPDDR5 in Rechenzentren, geeignet für KI-Agenten-Tools
- Speicher: BlueField 4 + CX 9, eine neue Speicherplattform für das KI-Zeitalter, alle Speicheranbieter sind dabei
- Spectrum X: weltweit erster massenproduzierter optischer (CPO) Ethernet-Switch, voll in Produktion
- Kyber-Rack: neues Rack-System, unterstützt 144 GPU in einer NVLink-Domäne, mit Front-Computing und NVLink-Switching im Backend, bildet eine riesige Rechenmaschine
- Rubin Ultra: nächste Generation des Supercomputers, vertikal eingebaut, mit Kyber-Rack, für noch größere NVLink-Interconnects
Vera Rubin ist vollständig flüssigkeitsgekühlt, die Installation dauert nur noch zwei Stunden (vorher zwei Tage), mit 45°C heißem Wasser gekühlt, was die Kühlkosten im Rechenzentrum deutlich senkt. Satya Nadella hat bereits bestätigt, dass die erste Vera Rubin-Instanz bei Microsoft Azure läuft – ich bin begeistert.
Groq-Integration: Extremer Durchsatz bei Inferenz
Wir haben das Groq-Team übernommen und die Technologie lizenziert. Groq ist ein deterministischer Datenflussprozessor (Deterministic Dataflow Processor), der mit statischer Kompilierung und Compiler-Optimierung arbeitet, viel SRAM hat und speziell für Inferenz-Workloads entwickelt wurde – extrem niedrige Latenz und hohe Token-Generation.
Allerdings ist Groq mit nur 500 MB SRAM auf dem Chip begrenzt, was die eigenständige Verarbeitung großer Modelle erschwert.
Lösung: Dynamo – eine Software für Inferenz-Management. Mit Dynamo entkoppeln wir die Inferenz-Pipeline:
- **Pre-filling (Vorladen) und Attention-Mechanismen (Decoding) laufen auf Vera Rubin (hoher Rechenbedarf, KV-Cache)
- **Feed-Forward-Netzwerke (Token-Generation) auf Groq (hohe Bandbreite, niedrige Latenz)
Diese beiden Komponenten sind über Ethernet eng verbunden, mit spezieller Steuerung, um die Latenz um etwa die Hälfte zu reduzieren. Unter dem Dach des „AI Factory Operating System“ Dynamo steigt die Gesamtleistung um das 35-fache, und es entstehen völlig neue Inferenz-Performance-Level, die vorher mit NVLink 72 nicht erreichbar waren.
Die Kombination Groq + Vera Rubin empfiehlt sich:
- Bei vorwiegend hohem Durchsatz: 100 % Vera Rubin
- Bei hoher Wertschöpfung durch Code-Generation: 25 % Groq + 75 % Vera Rubin
Groq LP30 Chips, gefertigt von Samsung, sind bereits in Massenproduktion, Auslieferung ab Q3. Danke an Samsung für die Unterstützung.
Historischer Sprung bei Inferenz-Leistung
Vergleich: Innerhalb von zwei Jahren steigt die Token-Generation in einem 1-GW-KI-Fabrik-Cluster von 22 Millionen auf 700 Millionen pro Sekunde – 350-fach. Das ist die Kraft des extremen Co-designs.
Roadmap
- Blackwell: aktuell in Produktion, Oberon-Standardrack, Erweiterung auf NVLink 72, optional auf NVLink 576 mit Lichtwellenleiter
- Vera Rubin (aktuell): Kyber-Rack, NVLink 144 (Kupfer); Oberon-Rack, NVLink 72 + Lichtwellenleiter, Erweiterung auf NVLink 576; Spectrum 6, erster CPO
